ประวัติและความเป็นมาของเทคโนโลยี computer vision
การทดลองรุ่นแรกเริ่มที่เกี่ยวข้องกับเทคโนโลยี computer vision นั้น เริ่มต้นขึ้นในทศวรรษ 1950 โดยใช้ประโยชน์จากนวัตกรรม neural networks รุ่นแรกสุด ด้วยความพยายามที่จะค้นหาขอบและมุมของวัตถุต่าง ๆ และจัดหมวดหมู่ให้แก่รูปทรงอย่างง่าย เช่น รูปทรงกลม หรือรูปสี่เหลี่ยม เป็นต้น ต่อมาในช่วงทศวรรษ 1970 นั้น ได้มีการนำเทคโนโลยีนี้มาใช้เพื่อการพาณิชย์เป็นครั้งแรกโดยการตีความตัวอักษรที่ถูกเขียนหรือพิมพ์ ด้วยเทคนิคการประมวลผลที่เรียกว่า optical character recognition ซึ่งนำไปสู่การตีความตัวหนังสือและข้อความที่เกิดจากการเขียนหรือสิ่งตีพิมพ์ให้แก่ผู้พิการทางสายตา
การพัฒนาสู่จุดสูงสุดของอินเทอร์เน็ตในช่วงทศวรรษที่ 1990 นั้นส่งผลให้รูปภาพปริมาณมหาศาลถูกนำขึ้นยังระบบออนไลน์และสามารถถูกนำมาทำการวิเคราะห์ได้อย่างไม่หยุดยั้ง ซึ่งเป็นปัจจัยกระตุ้นชั้นดีสำหรับการเติบโตของโปรแกรมการจดจำใบหน้า ข้อมูลปริมาณนับไม่ถ้วนเหล่านี้เติบโตอยู่ตลอดเวลา และช่วยให้อุปกรณ์ต่าง ๆ สามารถทำการระบุตัวตนและจดจำผู้คนต่าง ๆ ได้จากภาพถ่ายและวิดีโอ
ในทุกวันนี้ มีหลายปัจจัยที่เป็นผลบวกต่อการพัฒนาอย่างก้าวกระโดดในวิทยาการด้าน computer vision ซึ่งได้แก่:

อุปกรณ์พกพาและโทรศัพท์ ซึ่งมีกล้องถ่ายภาพในตัว ได้ทำให้โลกปัจจุบันนี้เต็มไปด้วยภาพถ่ายและวิดีโอต่าง ๆ ปริมาณนับไม่ถ้วน

ระบบประมวลผลที่มีประสิทธิภาพสูงมีต้นทุนที่ต่ำลงมาก และผู้เล่นรายต่าง ๆ สามารถเข้าถึงเทคโนโลยีดังกล่าวได้มากกว่าในอดีต

อุปกรณ์ฮาร์ดแวร์ที่ออกแบบมาสำหรับงานด้าน computer vision และการวิเคราะห์ด้วยระบบคอมพิวเตอร์นั้นยังมีการแพร่หลายและเข้าถึงได้มากกว่าที่เคยมีมาอีกด้วย
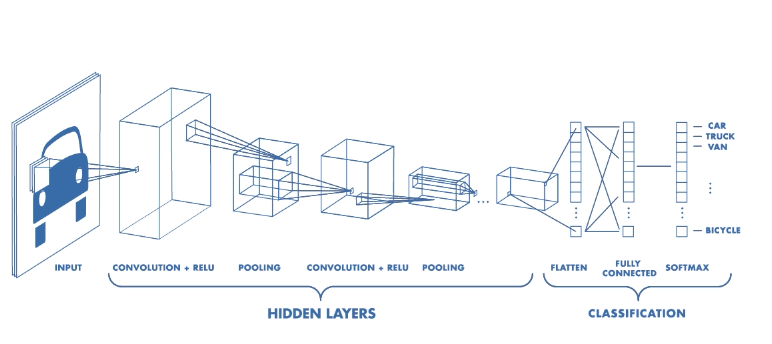
อัลกอริทึมที่ทันสมัยเช่น convolutional neural networks สามารถใช้ประโยชน์จากพลังของฮาร์ดแวร์และซอฟท์แวร์ที่ทันสมัยในยุคปัจจุบันได้อย่างเต็มศักยภาพ
ผลของความก้าวหน้าทางเทคโนโลยีเหล่านี้ต่อการพัฒนาด้าน computer vision นั้น เห็นได้อย่างชัดเจน อัตราความแม่นยำของการระบุวัตถุต่าง ๆ และการจัดหมวดหมู่ข้อมูลได้ยกระดับขึ้นจากความแม่นยำร้อยละ 50 มาอยู่ที่ร้อยละ 99 ภายในเวลาไม่ถึงหนึ่งทศวรรษ และระบบในปัจจุบันนี้สามารถตรวจจับและตอบสนองต่อข้อมูลเชิงภาพต่าง ๆ ได้อย่างแม่นยำยิ่งกว่ามนุษย์แล้ว
การทำงานของ computer vision
เทคโนโลยีการแยกแยะและจดจำภาพนี้มีขั้นตอนการทำงานพื้นฐานสามขั้นด้วยกัน ดังนี้
การจับภาพหรือนำเข้าข้อมูลภาพ
ภาพต่างๆ หรือแม้แต่รูปภาพจำนวนมากสามารถที่จะถูกนำเข้าในระบบได้ผ่านวิดีโอ ภาพถ่าย หรือแม้แต่ภาพสามมิติ เพื่อทำการวิเคราะห์ในขั้นต่อไป
การประมวลผลจากภาพ
โดยมากแล้ว แบบจำลอง deep learning จะทำงานในขั้นตอนนี้โดยอัตโนมัติ อย่างไรก็ตาม แบบจำลองที่จะสามารถทำงานได้ดังกล่าว จะต้องได้รับการ "ฝึกฝน" เสียก่อน ด้วยการป้อนข้อมูลภาพจำนวนหลายพันภาพ โดยมีการให้เฉลยหรือ labels หรือมีการระบุวัตถุในภาพก่อนในขั้นตอนของการเรียนรู้
การทำความเข้าใจเพื่อตีความภาพ
ขั้นตอนสุดท้ายของการทำงานคือการตีความ ซึ่งวัตถุที่ปรากฏจะถูกระบุชนิดหรือจัดประเภทในขั้นตอนนี้
ระบบ AI ในปัจจุบันนั้น มีประสิทธิภาพสูง และสามารถดำเนินการต่อยอดจากผลลัพธ์ที่ได้รับ และนำข้อมูลจากการทำความเข้าใจภาพมาใช้ให้เกิดประโยชน์ต่อไปได้ ซึ่งมีรูปแบบของเทคโนโลยี computer vision หรือคอมพิวเตอร์วิทัศน์หลายรูปแบบ และมีการใช้งานในหลายสถานการณ์ตามไปด้วย ดังนี้:
- Image segmentation - คือการแยกส่วนของภาพออกเป็นหลาย ๆ ส่วนหรือชิ้นองค์ประกอบย่อย ๆ เพื่อพิจารณาแยกส่วนกัน
- Object detection - หรือการตรวจหาวัตถุแบบเฉพาะเจาะจงในภาพแต่ละภาพ ซึ่งมีการทำงานในระดับสูงที่สามารถระบุวัตถุหลายชิ้นในภาพเดียวกันได้ เช่น ในภาพของการแข่งขันฟุตบอลนั้น อาจระบุวัตถุต่าง ๆ ได้แก่ สนามฟุตบอล ผู้เล่นฝั่งทีมรุก ผู้เล่นฝั่งทีมรับ ฯลฯ โดยการทำงานของแบบจำลองการวิเคราะห์นี้อาศัยการทำจุดพิกัดตามแกน X และ Y เพื่อสร้างกล่องสำหรับการพิจารณา และระบุวัตถุทุกชิ้นที่อยู่ในในพื้นที่กล่องแต่ละกล่องที่กำหนดขึ้น
- Facial recognition - หรือการจดจำใบหน้า เป็นรูปแบบการระบุวัตถุขั้นสูงที่มิได้ทำแค่การระบุว่ามีใบหน้าของมนุษย์อยู่ในภาพเท่านั้น แต่ยังสามารถแยกแยะบุคคลแต่ละบุคคลออกจากกันและระบุบุคคลที่เจาะจงได้อีกด้วย
- Edge detection - เป็นเทคนิคการระบุหาขอบหรือมุมของวัตถุ หรือภาพทิวทัศน์ เพื่อให้ทราบได้ง่ายขึ้นว่าองค์ประกอบในภาพมีสิ่งใดบ้าง
- Pattern detection - คือการระบุวัตถุจากรูปทรง หรือสี หรือสิ่งบ่งชี้ต่าง ๆ ที่พบในภาพ ที่เป็นรูปแบบเดียวกันซ้ำ ๆ สำหรับวัตถุประเภทนั้น ๆ
- Image classification - ทำงานด้วยการจัดกลุ่มภาพออกเป็นหมวดหมู่ต่าง ๆ
- Feature matching - เป็นรูปแบบหนึ่งของการตรวจหารูปแบบหรือ pattern detection ที่ระบุจุดที่เหมือนหรือคล้ายคลึงกันในภาพต่าง ๆ เพื่อจัดหมวดหมู่แก่วัตถุและภาพเหล่านั้น
การใช้งานอย่างง่ายสำหรับ computer vision นั้น อาจใช้เทคนิคที่กล่าวมาเพียงไม่กี่ประเภทเท่านั้น แต่สำหรับการทำงานที่ซับซ้อนอย่างยิ่ง เช่น ยานพาหนะที่ขับเคลื่อนด้วยตัวเองหรือ self-driving vehicles นั้น จำเป็นต้องอาศัยเทคนิคหลากหลายแบบผสมผสานกัน
แล้ว Computer Vision ช่วยขับเคลื่อนอนาคตได้อย่างไร
ในยุคที่การพัฒนาของเทคโนโลยีถูกพัฒนามาอย่างก้าวกระโดด จาก10ปีก่อน จนถึงตอนนี้ เรามีโทรศัพท์ที่สามารถพูดคุยกันเห็นหน้า (Video Call) เรามีโทรศัพท์ที่สามารถสั่งการด้วยเสียง โต้ตอบกับเราด้วยคำพูด(Siri) และอื่นๆอีกมากมาย แต่เราก็ไม่สามารถรู้ได้เลยว่ามันจะพัฒนาไปได้ไกลอีกแค่ไหน ในเมื่อคอมพิวเตอร์ยังคงตาบอด
การพัฒนาของ Computer Vision นั้น ก็เปรียบกับการมอบดวงตาให้กับคอมพิวเตอร์ ความสามารถของคอมพิวเตอร์ ก็เพิ่มขึ้น อย่างที่เราเห็นข่าวของการพัฒนายานพาหนะไร้คนขับ หรือ หุ่นยนต์อัจฉริยะ และหากมันถูกพัฒนาไปไกลมากๆ เราอาจได้เห็นการใช้ Computer Vision ในวงการแพทย์ เช่น การแยกแยะเซลล์มะเร็ง หรือแยกแยะพวกเซลล์เม็ดเลือดดีร้ายได้แทนการมองเห็นของมนุษย์
อีกตัวอย่างที่เห็นได้ถึงประโยชน์ของ Computer Vision นั้นก็คือการที่ Facebook นำ AI ไปใช้ในการป้องกันคนใช้ Live streamimg ฆ่าตัวตาย นอกจากนี้หากมองถึงประโยชน์อีกด้าน ถ้าหากเรานำเทคนโนโลยีนี้มาช่วยป้องกันอาชญกรรมได้ล่ะ โดยใช้ Computer Vision เป็นหูเป็นตาในเขตชุมชนช่วยเฝ้าระวังการก่อการร้าย มันคงจะดีไม่น้อย และถึงแม้ว่ามันอาจจะฟังดูเป็นไปได้ยากแต่ก็ใช่ว่าจะเป็นไปไม่ได้เลย
หลายธุรกิจ โดยเฉพาะ ธุรกิจด้านการดูแลสุขภาพ ต่างก็ได้รับประโยชน์จากเทคโนโลยีการระบุรูปภาพนี้ โดยได้มีการพัฒนาด้านการแพทย์อย่างเครื่อง Dulight กล้องถ่ายภาพแบบสวมใส่ขนาดเล็กที่ใช้เทคโนโลยีนี้ในการะบุสิ่งของต่างๆ อย่างอาหาร เงิน และสัญญาณจราจร ซึ่งช่วยให้ผู้พิการทางสายตาได้รับรู้สิ่งต่างๆ ได้มากอย่างที่ไม่เคยเกิดขึ้นมาก่อน
หรืออีกตัวอย่างหนึ่งของการใช้ประโยชน์ด้านสุขภาพที่เห็นได้ชัด ได้แก่ การพัฒนาตู้เย็นที่สามารถบอกได้ว่าอาหารที่แช่เอาไว้ชิ้นไหนหมดอายุหรือเสียแล้วบ้างของแบรนด์พานาโซนิก
และแน่นอนว่าเทคโนโลยีนี้ได้เข้ามามีอิทธิพลต่อโลกการตลาดดิจิตอลแล้วเช่นกัน ด้วยความสามารถในการระบุรูปภาพทำให้เกิดรูปแบบการโฆษณาแบบใหม่ขึ้น คือ โฆษณาแบบ In-image
การโฆษณาแบบ In-image ใช้ประโยชน์จากซอฟต์แวร์ระบุรูปภาพเพื่อแสดงโฆษณาออนไลน์โดยอ้างอิงจากรูปภาพที่สอดคล้องกับโฆษณานั้นๆ เช่น เทคโนโลยีของบริษัท GumGum ที่สามารถจับรูปภาพในหน้าเว็บไซต์ข่าว หากเป็นรูปผู้ชายโกนหนวดเคราเกลี้ยงเกลา ระบบจะโชว์โฆษณาใบมีดโกนหนวดขึ้นมาภายในรูปภาพนั้น หรือหากเป็นรูปผู้หญิงยิ้มเห็นฟันขาว ระบบก็จะแสดงภาพโฆษณายาสีฟันขึ้นมา
เทคโนโลยี Image Recognition เปิดโอกาสให้สำนักข่าวออนไลน์ต่างๆ สร้างรายได้จากรูปภาพประกอบบทความของตนเอง ซึ่งเป็นสิ่งที่ไม่เคยเกิดขึ้นมาก่อน และในขณะเดียวกันก็สร้างเครื่องมือทางการตลาดให้กับนักการตลาดในรูปแบบที่ไม่เคยมีมาก่อนด้วย อย่างไรก็ตาม โอกาสที่เกิดขึ้นจากเทคโนโลยีนี้มีมากกว่านั้น เพราะทั้งหมดคือปรากฎการณ์ที่เรียกว่า Visual Web
ทุกวันนี้มีรูปภาพกว่า 2 พันล้านรูปถูกอัพโหลดเข้าสู่ระบบอินเทอร์เน็ต เว็บไซต์และแอพพลิเคชั่นที่เน้นการแชร์รูปภาพอย่าง Instagram และ Pinterest รวมทั้งกล้องถ่ายภาพบนสมาร์ทโฟนที่ใครๆ ก็มี คือช่องทางและเครื่องมือสำคัญในการแชร์ข้อมูลในรูปแบบรูปภาพดังกล่าว
หลายแบรนด์พยายามหาทางใช้ประโยชน์จากสิ่งที่เกิดขึ้นเพื่อสร้างคอนเทนต์แบบที่ผู้ใช้ผลิตขึ้นเอง (User-generated) แต่เป็นที่น่าแปลกใจว่า 80% ของรูปภาพที่เกี่ยวของกับแบรนด์มักไม่มีข้อความที่ชี้ให้เห็นถึงความเกี่ยวข้องกับแบรนด์ ดังนั้น จึงไม่สามารถติดตามหรือระบุรูปภาพเหล่านั้นได้ด้วยเครื่องมือ Social Listening แบบดั้งเดิมที่เคยใช้กันมา ซึ่งหมายความว่านักการตลาดก็ยังคงไม่สามารถใช้ประโยชน์จากปรากฎการณ์การแชร์รูปภาพที่กระหึ่มโลกออนไลน์ที่กำลังเกิดขึ้นได้
ดังนั้น เทคโนโลยีคอมพิวเตอร์วิทัศน์จะเข้ามาช่วยเพิ่มความสามารถในการตรวจจับและระบุรูปภาพเป็นสิบๆ ล้านภาพที่ถูกโพสต์สู่โลกออนไลน์ได้แบบเรียลไทม์ ซึ่งจะสร้างช่องทางที่ทรงประสิทธิภาพที่จะช่วยให้แบรนด์สามารถเข้าถึงลูกค้าได้โดยตรง
สุดท้ายนี้ การพัฒนาของเทคโนโลยีนั้น ก็เพื่อเพิ่มขีดความสามารถของมนุษย์ เราอาจจะมีคอมพิวเตอร์ที่มีดวงตาดีกว่ามนุษย์เป็น 100หรือ1000 เท่า แต่ถ้าหลายคนยังขาดความเชื่อมั่นในเทคโนโลยีเหล่านี้ สิ่งเหล่านั้นก็คงยังไม่ได้นำมาใช้ให้เกิดประโยชน์ เพราะฉะนั้นแล้วการที่ทุกคนเรียนรู้และเข้าใจเทคโนโลยี ก็เป็นสิ่งที่ช่วยผลักดันอนาคตได้เช่นกัน
0 ความคิดเห็น:
แสดงความคิดเห็น